The Data Flow is where you'll construct your data flow diagram, representing the flow of data from the data source to the target.
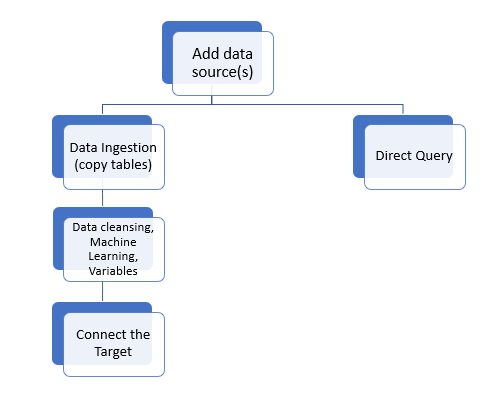
The first step in the data flow is to connect to one or more data sources; you can then copy the required tables into the data flow, or enable direct querying (see below) for the source.
If you've copied tables to the data flow, you can then apply a range of data manipulations and cleansing functions before loading the ETL into a target.
ETL Workflow
Your data flow will begin with at least one selected data source; this could be a file, web source, relational database, unstructured database, or a scripted source. Once you select your data source, Pyramid will prompt you to select which tables to copy from the source.
Some data sources support direct querying, meaning that they can be natively queries by Pyramid directly from Discover and Formulate. In this case, you don't need to copy any data into Pyramid or add a target server to the data flow, as Pyramid will directly query the source.
If you are creating a new data model in Pyramid (as opposed to directly querying the data source), then you'll need to select which tables and columns to copy into the new Pyramid data model. You can then perform a range of manipulations and operations on the tables or columns in order to clean the model and ensure that only the required data is copied from the source.
Finally, you'll need to connect a target to the data flow. This is the server onto which the data set will be loaded and where the data model will be stored. Once you've configured the target server, you can move onto Data Modeling.
Building the data flow involves the following steps:
Data Flow Interface
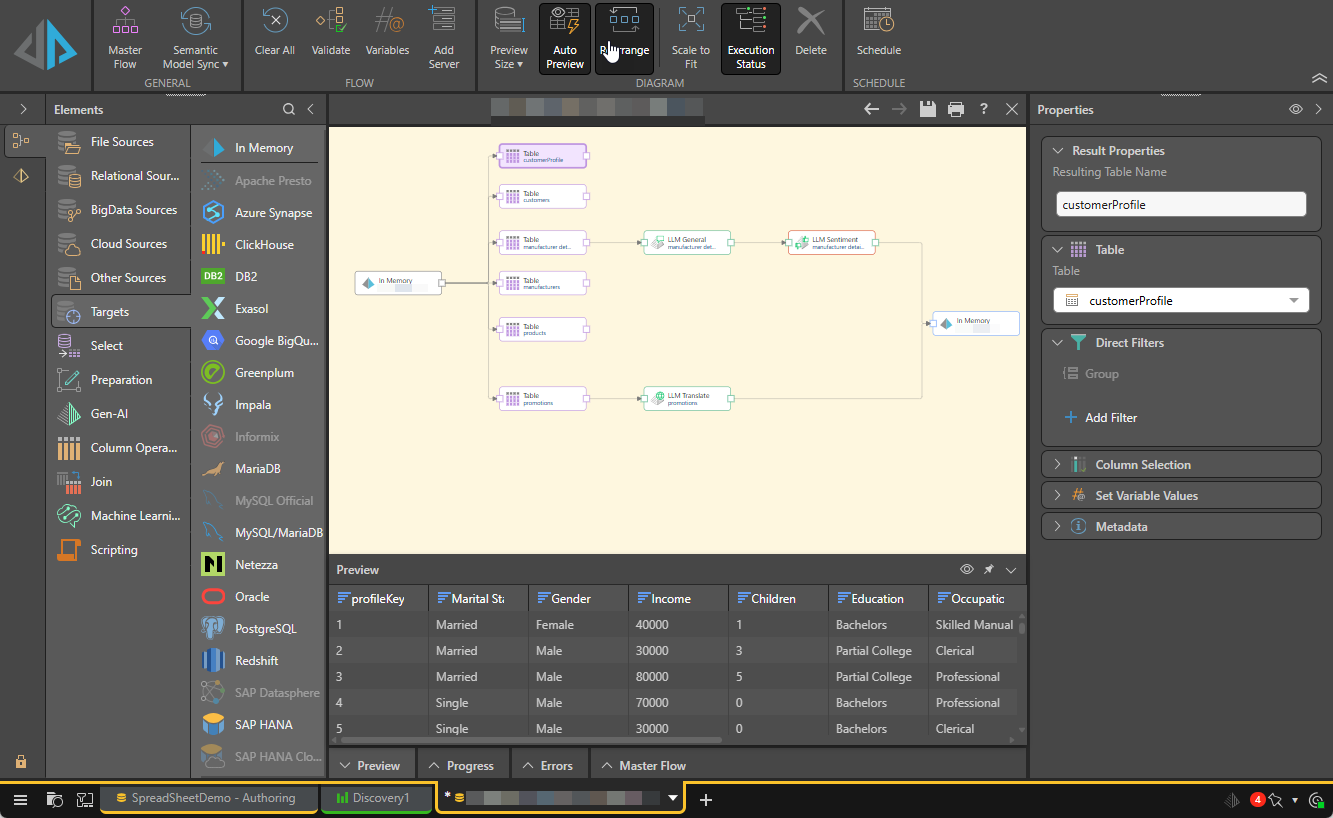
The Data Flow interface is comprised of several components, including the canvas, the ribbon, and several panels (Properties, Preview, Progress, and Errors), and the Elements panels, from where you can add data sources, targets, functions, and machine learning to the data flow.
- Click here to learn about the Data Flow interface.
Data Sources
Start the Data Flow (ETL) by connecting to at least one data source. Pyramid supports a range of data sources, many of which can be queried directly. Other sources require you to copy tables from the source into the data flow (this is known as data ingestion).
You can connect the data flow to a single source, or you can copy tables from multiple sources and join them to create a data mashup.
- Click here to learn how to connect to the data sources.
- Click here to learn about direct querying and data ingestion.
Targets
If your data flow is based on data ingestion, you'll need to connect it to a target node. The ETL will then be loaded from the source into the target, where it's stored. Pyramid supports a range of targets, including files, Pyramid IMDB, relational databases, and big data and unstructured databases.
Once you've connected the target, you can configure several properties for the table outputs.
- Click here to learn how to connect to the targets.
- Click here to learn about configuring table outputs.
Select
The select functions enable quick selection of multiple or individual tables directly from the data source, or to filter a specified table by a given number of rows.
These functions can also be accessed directly from the source node, when copying tables from the source.
- Click here to learn about the Select functions.
Gen-AI
The Gen-AI functions are used to transform data using Generative AI. Add these nodes to your Data Flow to use an LLM to automatically translate data, asses the sentiment contained by data, and transform data in response to your own natural language prompts (general).
- Click here to learn about using Generative AI nodes.
Preparation
These functions are used to transform data and optimize tables and columns for end-users by generation addition logic and columns, such as the creation of new date-time columns based on various date parts, generating latitude and longitude columns, and adding random number columns. These functions are also used for data cleansing, like sorting and filtering columns, removing duplicate rows, and transforming matrix grids into tabular ones so that they can be queried.
- Click here to learn about the Preparation functions.
Column Operations
The Column Operations nodes are used to edit, manipulate, or calculate values in the table columns. A range of functions allow you to perform basic edits like renaming columns, converting data types, and reordering columns in the table. You can also create calculation columns based on your own PQL expression, generate new date columns by adding or subtracting date parts from an existing date-time column, and more.
- Click here to learn about Column Operations.
Joins
The Join operations are used to combine tables together - either laterally or vertically. Joins and Unions can be added to the data flow to add them to the database schema.
- Click here to learn about Joins.
Machine Learning
In Pyramid, machine learning is manifested in a variety of ways. In fact, much of the platform is designed around the idea that ML is and will continue to be central to the BI platform and its users.
- Click here to learn about Machine Learning.
Scripting
The scripting engines allow users to manipulate data during the ETL. Using Marketplace, users can choose from a collection of scripts in a variety of languages. Using R or Python, users are able to write code on top of Pyramid data, to create customized columns and tables.
- Click here to learn about Scripting.